
新论文:面向建筑领域自然语言处理的领域语料库及预训练模型

DOI:https://doi.org/10.1016/j.compind.2022.103733
50 天免费访问链接: https://authors.elsevier.com/a/1fHOibquFR5MK
00
太长不看版
大家很重视AI在建筑领域的应用。建筑行业中存在大量文本信息(例如工程规范,合同及施组文档),该类文本具有丰富的领域概念及语义特征,蕴含复杂的领域知识。例如,每个工程师都可以轻松理解“甲、乙类厂房和甲、乙、丙类仓库内的防火墙,其耐火极限不应低于4.00h。”这句话,但是计算机是否可以自动理解呢?自然语言处理技术有望在这方面取得突破,实现自动化的文本信息处理与知识共享,降低人工投入,实现行业转型升级。
但是,建筑领域现有基于深度学习的自然语言处理模型仍然依赖大量人工数据标注(俗话说:有多少智能,就有多少人工)。因此,本文探索了在不增加额外人工标注的情况下,利用领域文本先验知识提升模型性能的方法。具体工作包括:(1)建立并公开了建筑领域语料库,(2)系统探索了不同类型的语料与预训练方法对于模型的提升效果,(3)提出了建筑领域预训练模型ARCBERT,可从无标注语料里自动学习领域知识,并大幅提升领域多种自然语言处理任务的效果。
01
摘要
作为建筑行业的重要任务,基于自然语言处理(Natural language processing, NLP)的非结构化文本数据的信息处理和获取正受到越来越多的关注。随着深度学习(Deep learning,DL)技术和用于模型预训练的开放数据集的发展,许多NLP方法也得到了进一步的发展和改进。但是,目前在AEC领域中很少研究特定领域预训练语言模型(Domain-specific pretrained language model)及其优势。主要原因是(1)缺乏统一公开供模型评价的数据集,(2)很少有公开的领域语料可供进一步研究。
在AEC领域,基于深度学习的方法仍然需要非常昂贵的人工标注来准备大量的训练数据集。因此,需要探索领域无标签语料库如何影响基于深度学习的AEC领域NLP任务的性能,从而进一步提升模型的性能。
针对上述问题,本研究的技术路线图如图1所示。具体而言,本研究首先开发了建筑领域语料库(已开源,访问链接:https://github.com/SkydustZ/AEC-domain-corpora/tree/main/domain%20corpus)。然后,基于两类领域语料库(域内,in-domain 和 近域,close-domain)及两种预训练方法(静态词向量,static word embedding 和动态词向量,contextual word embedding)训练了多种预训练语言模型。在此基础上,本文将自动规则检查(Automated Rule Checking,ARC)中的两种下游任务(即文本分类(TC)和命名实体识别(NER))作为典型案例,系统研究了预训练语料与方法对于深度学习模型的性能影响。值得一提的是,基于本文所开发域语料库进一步预训练得到了ARCBERT模型,该模型在ARC的典型下游NLP任务上获得了最优结果,超过了其他所有模型。这意味着无需额外人工标注,即可通过领域语料先验知识自动学习大幅提升多种NLP任务的性能表表现。
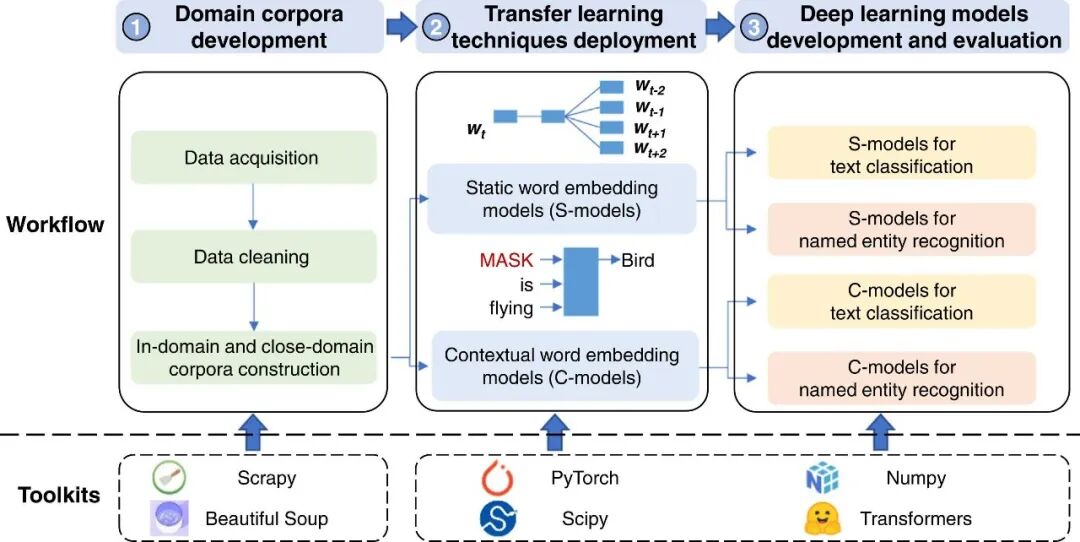
图1 领域语料与预训练方法增强深度学习模型的技术路线
02
领域语料库开发
首先,这项工作收集了大量的领域语料,随后分别构建了域内语料库(in-domain,此类语料由土木工程法规文本组成,也是ARC任务处理的目标语料,因此称为in-domain)和近域语料库(close-domain,此类语料由土木工程语料组成包括土木工程百科词条等,与ARC语料接近,因此称为close-domain)。
语料库建立方法:爬虫爬取相关文本,数据清理(无关内容过滤,长文本拆分)。所构建的领域语料如表1所示。
表1 领域语料库的统计数据

03
预训练模型
预训练词向量模型分可为静态词向量模型(static word embedding model)和动态词向量模型(或称为上下文相关词向量模型,contextual word embedding model)。静态词向量模型假设任何单词的语义不会随上下文发生变化。动态词向量假设单词的语义会随上下文发生变化。
对于静态词向量模型训练,技术路线图如图2所示。采用维基百科中文语料与领域语料基于skip-gram model,训练四个词嵌入模型:(1)通用模型,使用维基百科中文语料库(简称Wiki语料库)进行训练;(2)域内模型,使用Wiki和域内语料库进行训练;(3)近域模型,使用Wiki和近域语料库进行训练;(4)混合域模型,使用Wiki、域内和近域语料库进行训练。
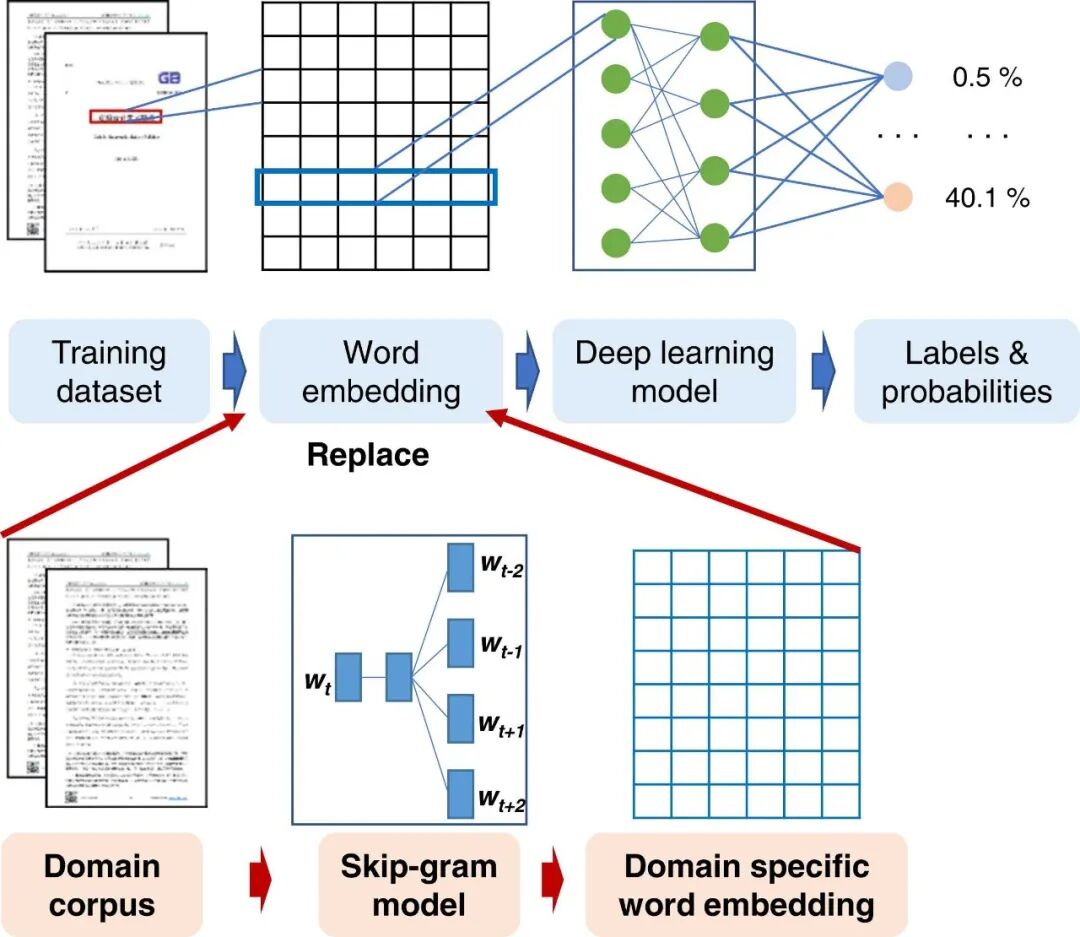
图2 建筑领域特定静态词向量模型增强深度学习模型的方法
对于动态词向量模型训练,技术路线图如图3所示。首先选择了两个基准模型(1)bert-base-chinese[1]和(2)ERNIE[2]。然后,对所构建的领域语料进行了组合与划分,以探索领域语料类型、数量的影响。具体包括:(1)域内语料库;(2)近域语料库;(3)混合领域语料库(混合域内和近域);(4)1/3的域内语料库;(5)1/5的域内语料库,共五种衍生语料库。
在此基础上,使用masked language model模型与上述五种领域语料库进行进一步预训练,训练了10个预训练模型,如表2所示。
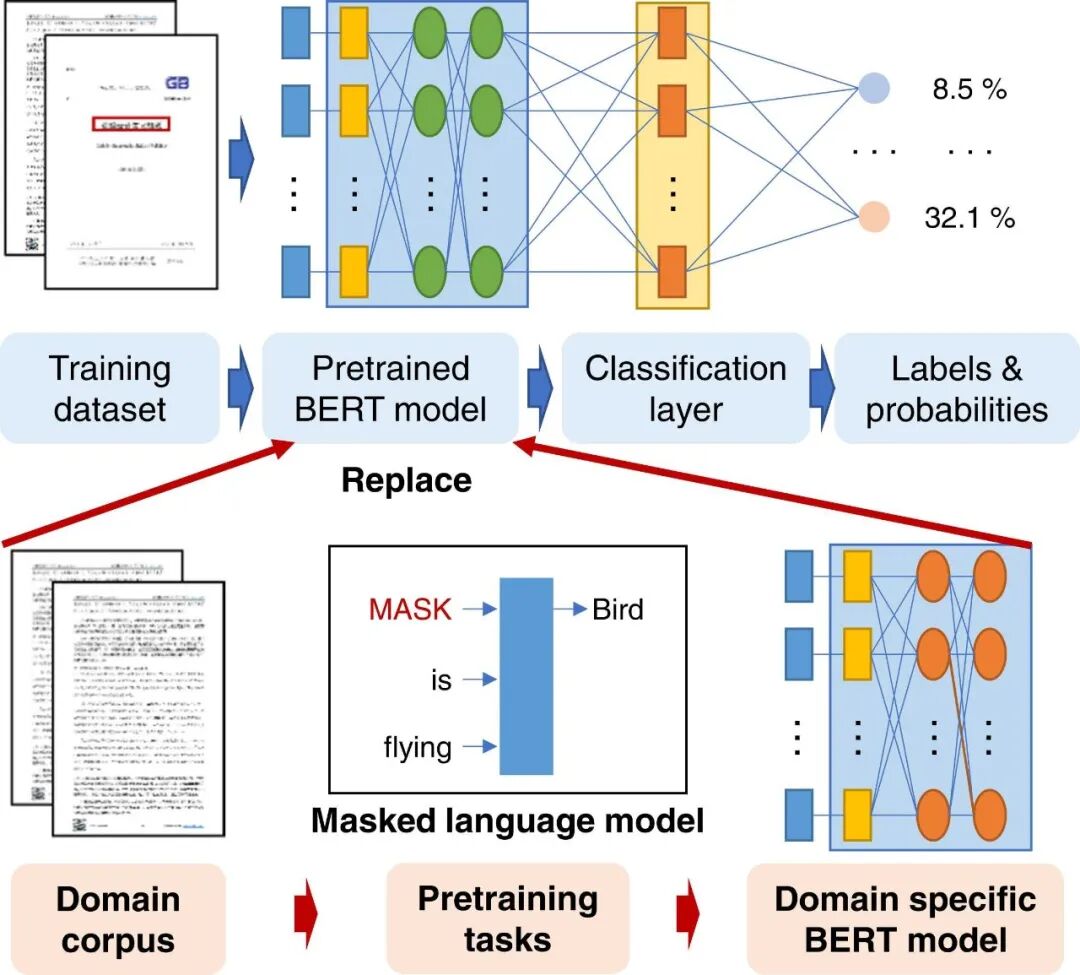
图3 建筑领域特定动态词向量模型增强深度学习模型的方法
表2 领域语料库的统计数据

04
深度学习模型提升效果评估
为了评价上述预训练模型对于深度学习模型的提升效果,本节开展了系列实验,以下是实验的配置。
(1)数据集选择:在两个数据集上评估本研究中的方法和领域语料库,包括法规TC数据集[3]和NER数据集[4]。
(2)指标选择:对于TC模型,选择加权F1(weighted F1)。对于 NER 模型,选择宏平均 F1(macro F1)进行结果的衡量。首先,计算每个语义标签的精度(P)、召回率(R)和F1分数(F1):
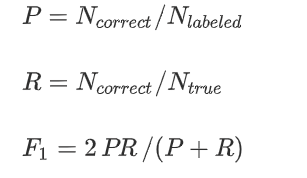
式中N {correct, labeled,true} 分别表示每个标签中{判断为标签正确的元素数,打标签的元素总数,实际标签正确的元素数}。
然后计算加权F1、宏平均F1:

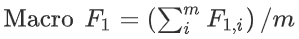
式中ni表示第 i 个语义标签的元素数;m表示语义标签类型的数量。
(3)数据集划分:将这两个数据集以 Train: Validation: Test = 0.8: 0.1: 0.1 的比例随机拆分。
(4)模型训练与微调:进行了四类实验,包括:1)静态词向量模型用于TC;2)静态词向量模型用于NER;3)进一步预训练动态词向量模型用于TC;4)进一步预训练动态词向量模型用于NER。
(5)实验结论:实验结果汇总图如图4、5所示。实验结果表明对于ARC的TC和NER任务,域内(in-domain)语料库可用于训练领域特定词向量模型或进一步预训练 BERT 和 ERNIE 模型以提高模型性能,无需额外的人工标注。
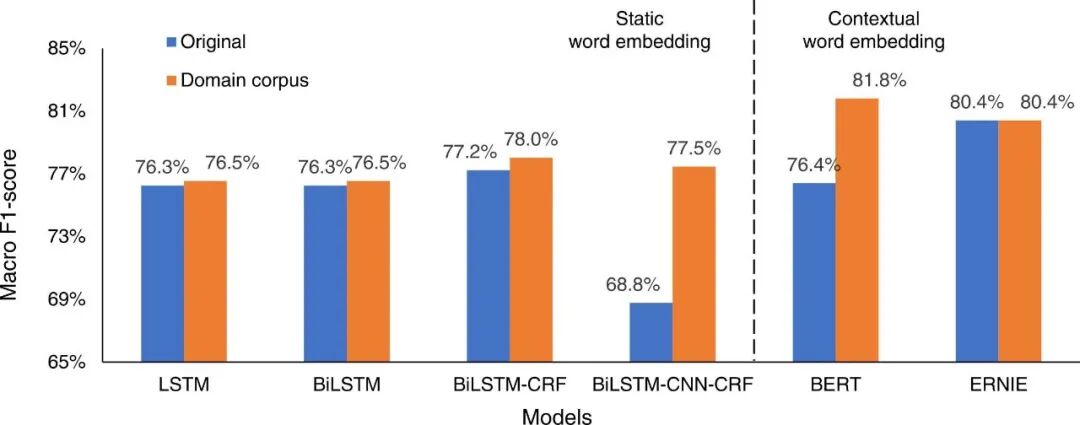
图4 各种模型在TC任务上的性能
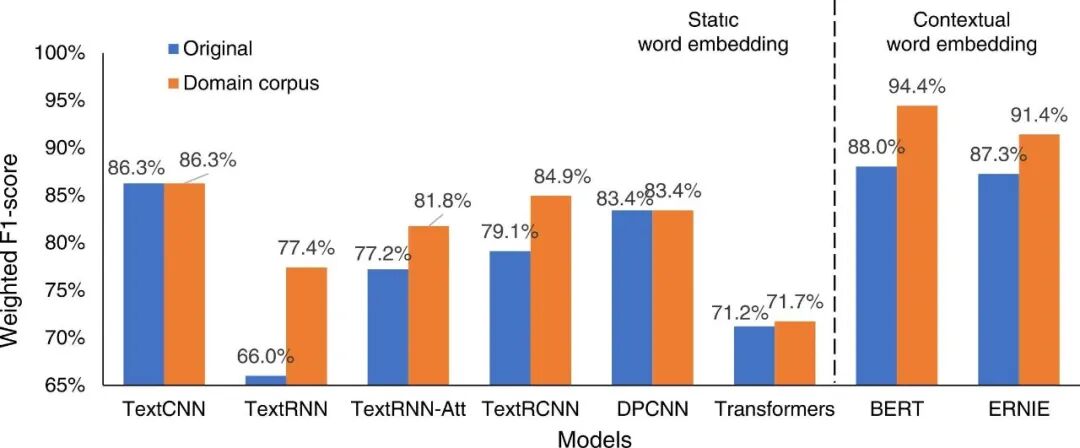
图5 各种模型在NER任务上的性能
05
结论
在这项研究中,系统地研究了领域语料库如何影响基于深度学习的方法在建筑领域中NLP任务的性能。首先,开发并公开了领域语料库,然后,基于四个实验,说明了开发的领域语料库和基于动态词向量模型的深度学习模型(例如BERT)的优势:
(1)对于TC和NER任务,领域语料库可以优化基于静态词向量的深度学习模型和基于动态词向量模型的深度学习模型。对于TC任务,两类模型加权 F1 分数分别提高了 11.4% 和 6.4%,对于NER任务,两类模型宏平均 F1 分别提高了 8.7% 和 5.4%。
(2)在领域语料库上预训练的BERT模型(ARCBERT)性能优于基于静态词向量的深度学习模型,TC的加权F1分数分别提高了8.1%,NER任务的宏平均F1分数分别提高了3.8%。基于动态词向量的深度学习模型(例如BERT和ERNIE)在NER和TC任务中的性能优于其他模型。
最后,本研究提出了一个在TC任务中的加权F1分数为94.4%的预训练模型,称为ARCBERT Large。同时提出了在NER任务中的宏平均F1为81.8%的预训练模型ARCBERT Small。这两个模型在TC和NER任务上取得了全局最优的效果。本研究开发的领域语料库和建筑领域预训练模型在各种NLP中显示出了良好的结果,可能为建筑领域的各种未来NLP相关的研究和应用提供启发。
[1] Hugging Face, 2019. Bert-base-chinese.https://huggingface.co/bert-base-chinese/tree/main
[2] Sun, Y., Wang, S., Li, Y., Feng, S., Chen, X., Zhang, H., Tian, X., Zhu, D., Tian, H., Wu, H., 2019. Ernie: Enhanced representation through knowledge integration. arXiv preprint arXiv:1904.09223.
[3] Zheng, Z., Zhou, Y.C., Chen, K.Y., Lu, X.Z., Lin, J.R., She, Z.T.,2022.Text classification-based approach for automatically evaluating building codes’ interpretability. (in preparation).
[4] Zhou, Y.C., Zheng, Z., Lin J.R., Lu X.Z., 2020. Deep natural language processing-based rule transformation for automated regulatory compliance checking. Preprint. https://doi.org/10.13140/RG.2.2.22993.45921.
---End---
相关研究
特刊征稿
专著
人工智能与机器学习
城市灾害模拟与韧性城市
高性能结构与防倒塌
新论文:抗震&防连续倒塌:一种新型构造措施
长按识别二维码,关注我们的科研动态
