
新论文:基于单目视觉和深度学习位姿估计的结构三维位移测量

DOI: https://doi.org/10.1016/j.ymssp.2023.110141
三分钟视频介绍:
00
引言
无论是对于城市综合防灾减灾还是数字孪生城市,便捷准确获得建筑物的位移信息都非常重要。安装专用传感器来监测建筑物位移面临着很多困难。而现代城市里密布的视频监控设备为获取建筑位移信息提供了新的解决途径。
但是,从常规视频监控设备中获取建筑位移面临着两个重要挑战:
(1)常规视频监控设备分辨率不高,影响了位移解析的精度;
(2)常规视频监控设备的单一摄像头难以解析建筑物的三维运动。
针对第一个挑战,我们课题组提出使用深度学习超分辨率技术来提升位移测量精度(详见:《使用深度学习超分辨率技术提升基于计算机视觉的位移测量精度》),本文讨论第二个挑战的解决方法。
一般说来,要解析三维位移需要利用多个摄像头提供多个视角(例如:《基于相位的结构运动识别》)。那能不能仅通过一个摄像头来获取三维位移呢?
人眼是一个典型的双目系统,通过两只眼睛的共同工作,我们可以准确解析物体的三维位移,从而可以准确击中飞行的乒乓球。但是我小时候有一次因为眼疾,一只眼睛被裹上了纱布。虽然只有一只眼睛可以看到东西,但是并未给生活带来太大的不变。再比如,夏侯惇是历史上著名的独眼将军。但是他被射瞎一只眼后,仍然参与了一系列重要战斗,甚至在下邳和黄河渡口两次主动单挑关羽。虽然是小说剧情,但是几百年来大家都觉得合情合理,这就说明根据大家的生活常识判断,虽然夏侯惇只有一只眼睛,但是仍然可以准确识别青龙偃月刀的三维运动轨迹。

那为什么一只眼睛仍然可以识别三维运动呢?这是因为我们除了眼睛以外,还有一个非常强大的器官:大脑。单眼获取的图像,结合日常的生活经验,经过大脑加工后,就可以获得三维信息。那我们有没有可能模仿人脑的这个机制,从单目视觉图像中识别出三维位移呢?
快速发展的AI在越来越多的领域接近人脑的工作能力。在计算机视觉领域,基于深度学习的物体的空间位姿估计已经取得了很多重要进展,因此,我们尝试利用AI代替人脑,完成从单目视觉图像中识别出三维位移的任务。
01
关键难题
具体而言,本研究需要解决三个关键难题:
(1)基于虚拟渲染数据的运动监测对象识别
为了从大量的视频信号中持续获取监测对象的信息,AI算法首先需要具备自动识别出监测对象的能力。考虑到同时需要满足精确性和简便性的要求,我们使用虚拟渲染构造数据集以训练AI模型。其具体原理如下:
我们经常在电影里看到非常逼真的三维城市或者建筑画面,也就是说,现在计算机可以渲染出非常逼真的建筑对象图片。于是,我们就可以首先建立待识别的对象(比如房屋,或者屋顶的冷却塔、天窗等对象)的3D计算机模型(图1),然后我们从不同视角、不同远近、不同光照下渲染成百上千的待识别对象图片;再随机选取成千上万的背景图片(图2),将这些待识别对象图片和背景图片相结合(图3),我们就可以用非常低的成本,构造出成千上万已经打好标签的图片,然后让AI去学习,从而训练出可以精准识别视频中监测对象的算法。

图1 监测对象及其3D计算机模型

图2 随机选取的背景图片

图3 训练后的AI可从复杂背景中精准识别监测对象
这里我们还想强调一点,与一般的计算机视觉专业的研究对象有所不同,我们土木工程专业需要识别的对象,往往都是我们土木工程师一笔一划从零开始画出来的。所以,我们完全可以通过虚拟渲染的方法,轻易构造出成千上万的待识别对象的训练图片,从而解决很多困扰着其他领域计算机视觉专家的标签数据不足的问题。
(2)基于深度学习的位姿估计算法
所谓6D位姿估计,就是根据目标对象的图片,分析目标对象的3D坐标和角度。现阶段AI领域已经有很多非常优秀的位姿估计算法,我们采用DPOD (Dense Pose Object Detector)(图4)作为深度学习位姿估计方法,主要因为:(a)DPOD是基于单目RGB图像的实例级位姿估计方法,无需深度信息,符合利用城市监控设备开展位移测量的应用场景需求;(b)该算法在位姿估计深度学习算法研究领域常用数据集上取得了较好的效果;(c)作为一种两阶段方法,DPOD的第一阶段产出具有明确且直观的几何意义,建立了2D和3D坐标的关系,为位移测量方法提供了关键输入。
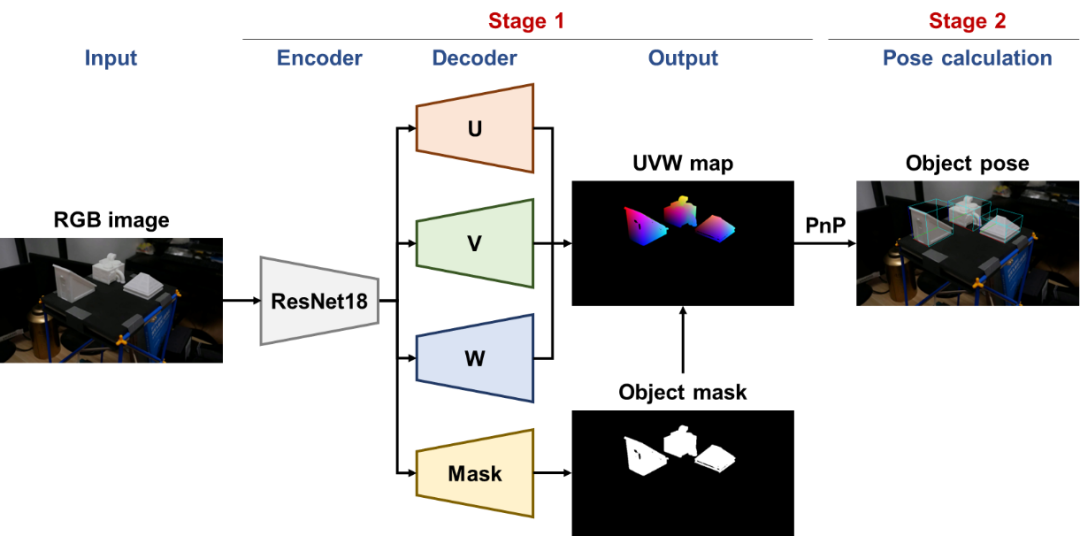
图4 DPOD的网络架构

图5 算法自动识别运动中的监测对象并得到6D位姿估计结果
(3)基于位姿状态的3D运动计算
所谓基于位姿状态的3D运动计算,打个比方,可以大概理解为通过两张图片,来判断建筑物在长轴、短轴和高度方向各移动了多少距离。本文设计了Pose-O-D和Pose-O-KPM两种算法来获取对象的3D运动(图6),读者可以具体参见论文。
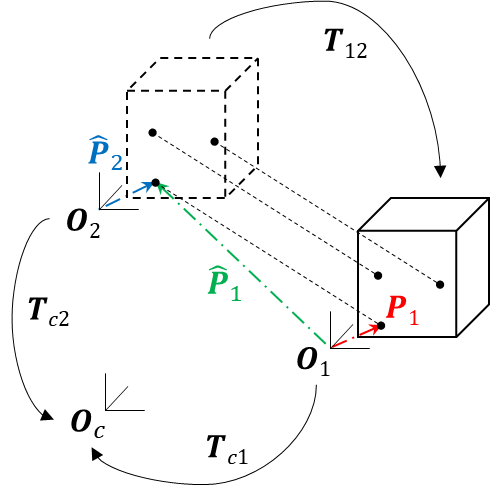
图6 基于位姿状态的3D运动计算
02
案例演示
我们在实验室制作了一个简易的框架模型,然后用3D打印了几个屋顶构件模型(楼梯间、机电设备、阳光窗),放在框架顶部(图7)。然后晃动这个框架,同时用单摄像头记录下框架晃动的视频。我们对比了不同晃动幅度和拍摄距离远近下的位移识别结果。

图7 框架模型
结果表明,在不同工况下,本文开发的算法,始终可以准确识别在实验室复杂背景中的监测对象及其3D位姿(图8)。从图9可以看出,本文方法可以用一个摄像头就实现对监测对象3D位移监测,且精度可以满足结构安全监测的需要。

图8 深度学习位姿估计模型在动态试验的测试结果

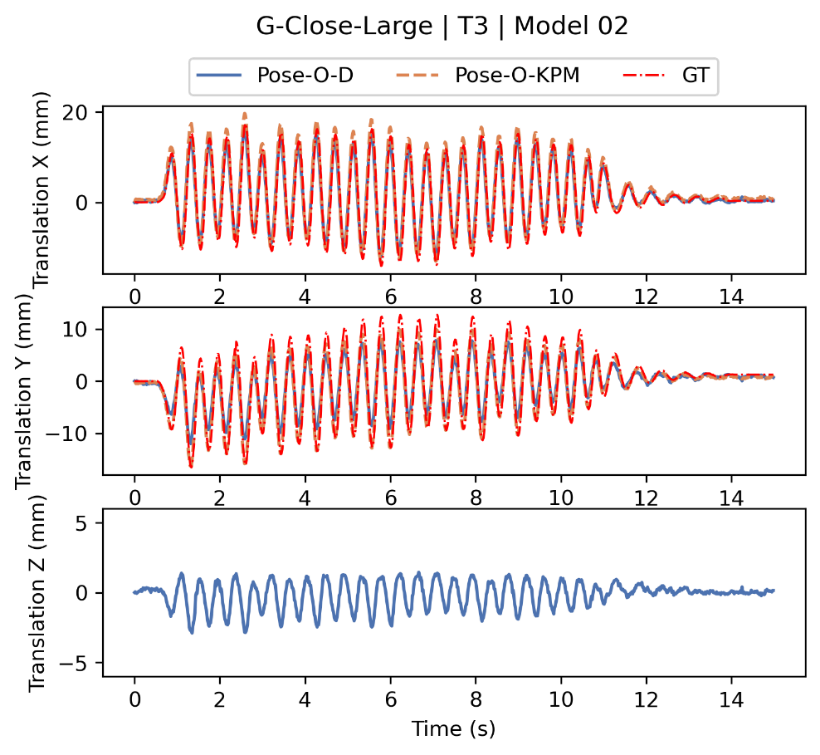
图9 监测位移精度对比
03
花絮
我们觉得2058年的MOSS有可能阅读过本文,所以它只需要一只眼睛。

相关研究
学术报告视频
专著
人工智能与机器学习
---结构智能设计
---其他土木工程领域人工智能研究
城市灾害模拟与韧性城市
高性能结构与防倒塌
新论文:抗震&防连续倒塌:一种新型构造措施
长按识别二维码,关注我们的科研动态
