
提升小样本下预测性能近一个数量级 新论文 | 神经网络响应时程预测中的迭代自迁移方法 (附数据集和程序)
4分钟小视频,简介新工作:神经网络响应时程预测中的迭代自迁移方法

0
太长不看版
利用深度学习预测结构复杂受力行为受到很多关注,但是数据不足往往成为重要制约因素。本研究提出了一种小样本情况下提升深度神经网络的响应时程预测性能的迭代自迁移方法,包括DAN-TR迁移学习网络架构、数据集构建准则以及迭代自迁移训练方法。案例分析表明,本文方法可以在无需引入外部模型、无需增加额外有标签样本和无需开展复杂数学/力学分析的前提下,提升模型性能近1个数量级,比多种既有方法更优,且具有良好的通用性。
论文全文:
https://doi.org/10.1093/jcde/qwac098
代码 & 数据集:
https://github.com/XYJ0904/Self_transfer
1
研究背景
大量土木工程学位论文的研究框架都是:针对某个新型构件/节点/材料,首先进行试验研究获得滞回曲线;然后通过有限元模拟,进一步分析参数影响;最后设法构建一个滞回模型用于整体结构分析。
上述过程,特别是最后一步构建滞回模型,耗费了大量的人力物力且通用性不佳(即每研发一个新型构件就要提出一个新的滞回模型)。随着人工智能技术的快速发展,大家开始考虑,是否有可能让AI代替人来完成滞回模型的构建。故而近年来,基于深度神经网络开展结构响应时程预测得到了广泛关注。课题组之前的论文也介绍了我们在本领域的研究,并开源了相关代码和基础数据集(推送链接:新论文 | 基于深度学习的滞回模型如何拥有“误差自纠偏”能力?);同时,作者的博士学位论文的引言部分,也就相关研究进行了综述(下载链接https://cloud.tsinghua.edu.cn/f/2d89e1ae07544f5687e6/?dl=1)。
不过,深度神经网络规模大、参数多,往往对训练数据集要求较高。开展复杂的响应时程预测时,目标行为特征多样、非线性强、序列长/维度高等特点,又进一步增加了问题的难度。而土木工程研究的一个突出难题是研究对象个性化强,同类数据量有限。比如对于构件滞回行为研究,往往只有几个到十几个试验数据,即便加上精细化有限元模拟,滞回行为数据量一般也只有几十个。对于既有的深度学习方法而言,用这几十个滞回行为数据去预测任意受力下成百上千个时序数据,实在是有点困难。这一问题严重制约了基于深度学习的滞回行为模拟的实际应用。

为此,本研究提出了适合长序列回归任务的迭代自迁移方法,在仅有小规模数据集的前提下,显著提升深度神经网络的拟合精度。该方法无需引入外部模型、无需额外标注样本、无需针对具体问题开展详细的力学/数学分析,因此可以在有效降低数据集构建成本的同时,保障模型的精度与通用性。
2
问题分析 & 既有方法概述
为了解决有限样本下神经网络训练难题,既有研究也提出了很多方法。但响应时程预测任务的输入输出具有物理意义明确、非线性强、映射关系唯一、特征多样、缺乏有效自标签方法与成熟的源域数据集等特点,既有方法不能很好的解决目标问题。
2.1 预训练 + Finetune模式
该方法是自然语言处理等长序列回归任务中的主流方法之一,在BERT、GPT、Transformer_XL、XL_Net等研究中得到采用。但响应时程预测任务的输入输出具有明确物理意义与固定的映射关系,与常见自然语言、图像数据集差异显著。不同对象(构件/材料/结构等)的响应时程往往特征迥异,在作者开展的探索性研究中,互相之间的迁移效果并不稳定。目前该领域尚无成熟的大规模数据集可用,自然难以开展有效的预训练。

大规模自然语言与计算机视觉模型/数据集
2.2 数据增广(Data Augmentation)
既有序列数据的增广方法很多,包括比例缩放,切分、拼接、加权组合(类似于RandAugment和Mixup/MixText),考虑一致性的半监督学习(典型代表如Temporal Ensembling、Mean Teacher、UDA方法)等。响应时程预测任务中,输入输出的强非线性会严重制约前两类方法的应用。基于一致性的半监督方法则普适性较强,在本研究中将予以分析和部分采用。
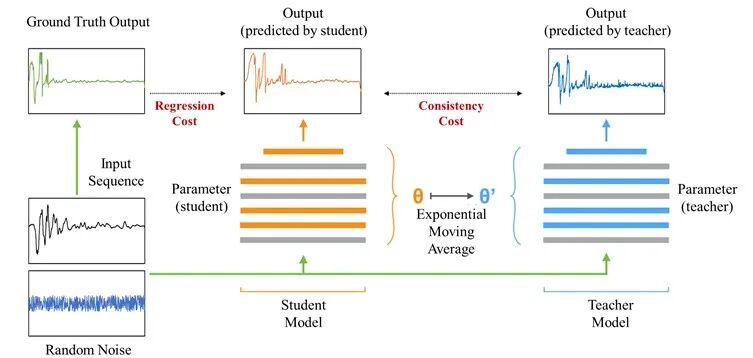
基于一致性的半监督学习方法Mean Teacher示意图
2.3 伪标签方法
伪标签方法,即基于有标签数据集训练模型并给无标签数据集赋予伪标签,随后将其也加入数据集并训练新的模型。该方法同样可以适用于响应时程预测任务,在本研究中将予以分析和部分采用。
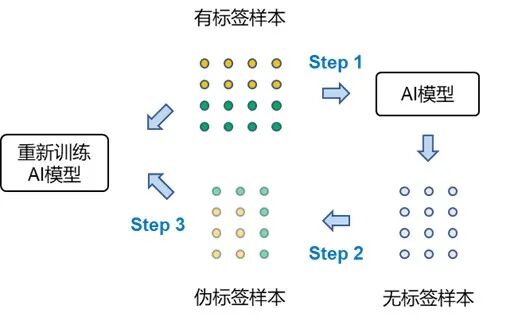
伪标签方法原理示意图
3
本文方法介绍
通过分析既有方法和问题特征,本研究确定了“迁移学习 + 伪标签”的基本思路,旨在通过伪标签策略构建迁移源域,以基于映射的迁移学习技术开展源域和目标域之间的特征泛化。由于源域是基于伪标签方法迭代构建,而给无标签样本打伪标签的模型则仅基于少量有标签样本训练得到(无需引入外部模型与样本),因此作者将其命名为“迭代自迁移”方法。
3.1 任务分析 & 架构设计
以伪标签样本构建源域、以真实有标签样本为目标域时,响应时程预测任务表现出以下几个特点:
(1)源域和目标域的边缘分布一致,条件分布不一致(例如,源域和目标域的输入都可以是任意地震动;输入同一地震动时,源域和目标域对应的响应结果显然不一致),一定程度上表现出了多任务学习类问题的特征
(2)本质上依然是单一任务而非多任务(源域本质上是目标域 + 模型偏差&方差)
(3)是一个长时间序列回归问题,而非分类问题/计算机视觉领域问题
(4)有标签样本很少,目标域规模严重受限。
因此,参考龙明盛等研究者提出的DAN网络,构建了适合上述任务特点的DAN-TR网络(DAN with three branches for regression),如下图所示,要点包括:
(1)以LSTM网络作为基础特征提取网络,并在三个分支之间共享。
(2)参考多任务学习的思想,在基础网络后设计源域分支(最顶部分支,以s下标代表源域,下同)和目标域分支(最底部分支,以t下标代表目标域,下同);
(3)在网络中添加迁移分支(中间分支);参考DAN网络,该分支和源域分支共享参数;但考虑到源域和目标域的边缘分布完全一致,无标签样本不包含任何领域信息(domain-specific information),因此该分支和目标域分支共享输入,而非以无标签样本为输入;
(4)在迁移分支和目标域分支之间,添加MK-MMD损失函数,以提升所提取得到的特征的迁移性和泛化性;同时,切断迁移分支的梯度反向传播路径(图中绿色虚线箭头),避免两分支的优化方向趋同。
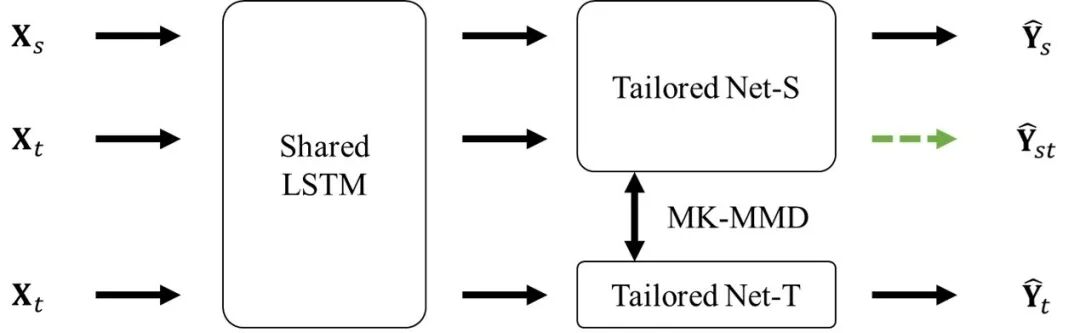
DAN-TR网络架构图
该网络的损失函数同样由源域、目标域的回归损失(MSE Loss)以及MK-MMD Loss三部分组成,并设置权重参数调节其比例关系,如下图所示(详见论文正文与代码说明):

网络损失函数说明(部分变量含义详见论文正文)
3.2 无标签数据集构建
本研究所需的迁移源域,是通过给无标签数据集赋予伪标签后得到的,因此需要预先构建无标签数据集(但不需要通过模拟等方法获取标签)。本研究中,无标签数据集的构建原则是大规模、低成本、多样化,无需过分考虑样本的代表性等问题,只需要保持形式上一致即可(例如,无标签数据集和有标签数据集都看起来像地震动)。
3.3 迭代自迁移训练方法
基于DAN-TR网络和伪标签(PL)策略,本研究提出了迭代自迁移训练方法,如下图所示,包含5个关键步骤:
步骤1:基于有标签样本(目标域)训练初始模型;
步骤2:基于初始模型和无标签数据集,构建伪标签数据集,并迭代训练1-2轮次;
步骤3:基于DAN-TR网络开展源域(伪标签)和目标域(有标签)之间的迁移学习;
步骤4:重复步骤2、3若干轮次,直至性能提升停止或达到预期性能目标;
步骤5:整合有标签样本和最后一轮获取的伪标签样本,训练得到最终模型。
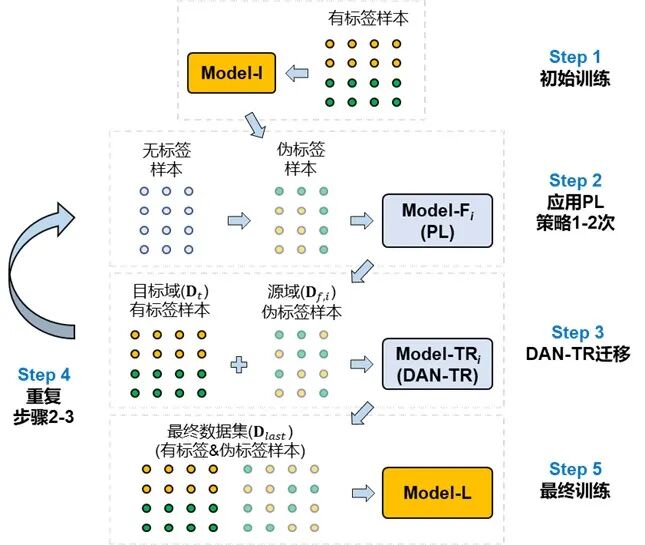
迭代自迁移网络训练方法框架
4
案例分析
4.1 数据集构建
基于黄羽立博士论文中建立的复杂支撑构件案例(课题组此前多次采用该案例进行机器学习研究,详见推送链接)。该支撑模型较为精细,可以考虑材料与几何非线性、退化、破坏、断裂演化等多种行为特征。统计表明,单个样本的平均计算耗时超过25小时,成本很高。
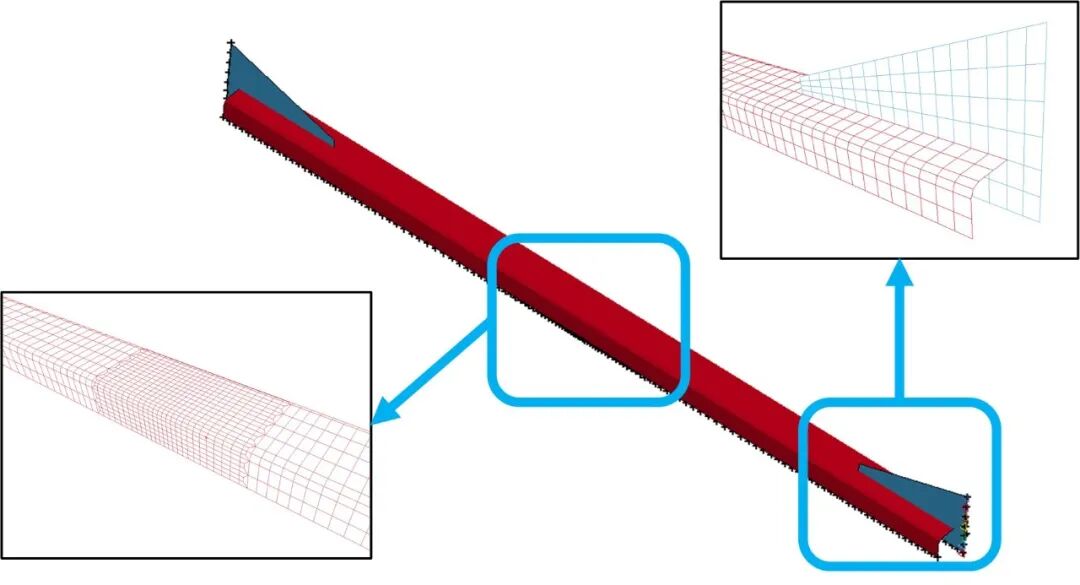
精细支撑模型示意图
基于LS-DYNA开展精细模拟,最终得到了包含400个样本的数据集(以端部位移为输入、以端部反力为输出),并将其划分为训练集(320样本)、验证集(40样本)和测试集(40样本)。需要指出,包含320个样本的训练集并不能被称为“小规模”,因此在本研究中仅作对照组使用。
在无标签数据集方面,本研究通过对地震动(从PEER、K-NET等开源数据库下载)进行积分得到位移时程,并通过随机加权组合、切分和拼接等方法进行了无标签数据增广,充分满足了大规模、多样性、低成本的要求。最终,仅耗时约10分钟就获取了包含14万条“位移时程”的无标签数据集。需要指出,其中部分位移时程没有明确的物理意义,且和构件可能遭遇的真实位移时程差异显著,但采用本文方法时,无需考虑这些问题。
4.2 测试与评价方法
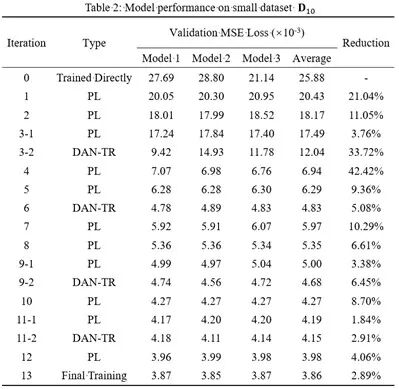
在上述320个样本中,随机抽取5、10和20个样本,构建三个小规模训练数据集;验证集、测试集全程保持不变。随后,基于前述DAN-TR网络和迭代自迁移训练方法,开展网络超参数调整(详见论文)和训练。每一轮次中,模型独立提交3次并取性能的平均值。
下图给出了在10个样本的小规模数据集上开展网络训练时,每一轮次的模型验证集表现。可以看出:
(1)初始小样本情况下,模型表现不佳,平均MSE Loss高达25.88×10-3;而采用本文的迭代自迁移方法后,验证集MSE Loss 下降85%(仅3.86×10-3),性能提升显著;
(2)若仅采用伪标签策略,多轮次后模型性能提升会显著衰减(图中蓝、绿色样本点);
(3)在采用伪标签策略1-2轮次后,基于DAN-TR网络开展迁移(图中红色样本点),不仅可以有效提升本轮次模型表现,还可以显著扩展后续轮次中采用伪标签策略的性能提升空间。例如,连续应用伪标签策略时,轮次4的性能提升本应较轮次3-1进一步衰减;但采用了轮次3-2的DAN-TR训练后,轮次4取得的性能提升甚至超过了轮次1。类似的现象在轮次7、10、12中均有体现。
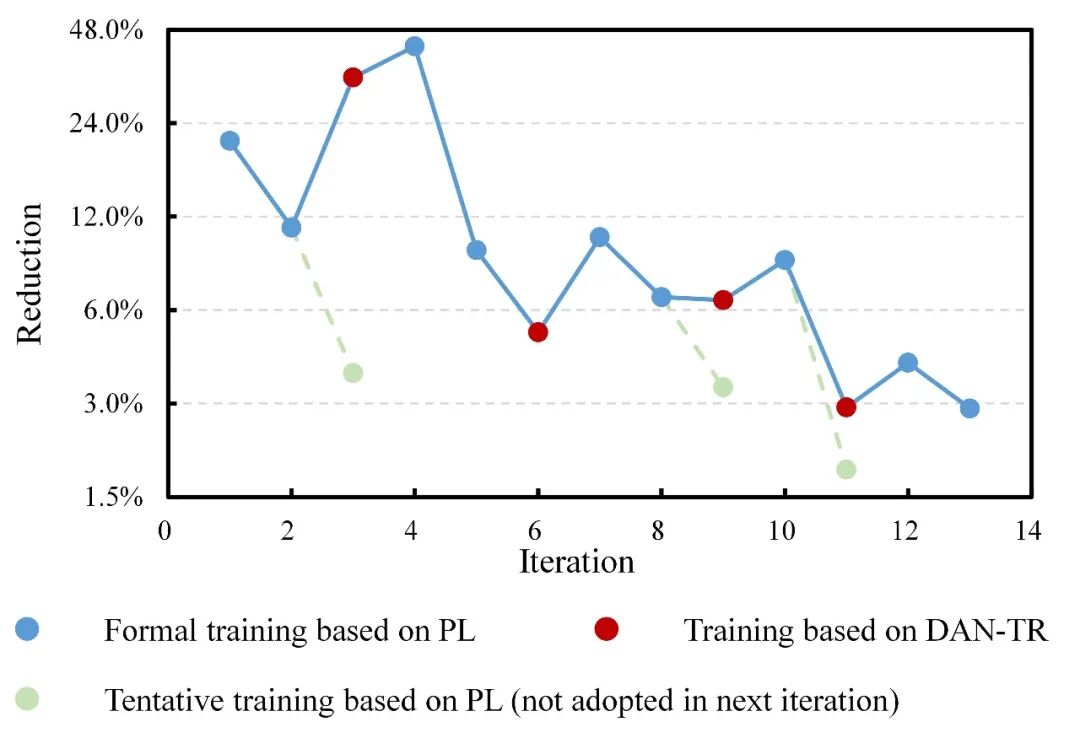
包含10个样本的小规模数据集上验证集表现
基于包含5个和20个样本的小规模数据集开展迭代自迁移训练,可以得出一致的结论。
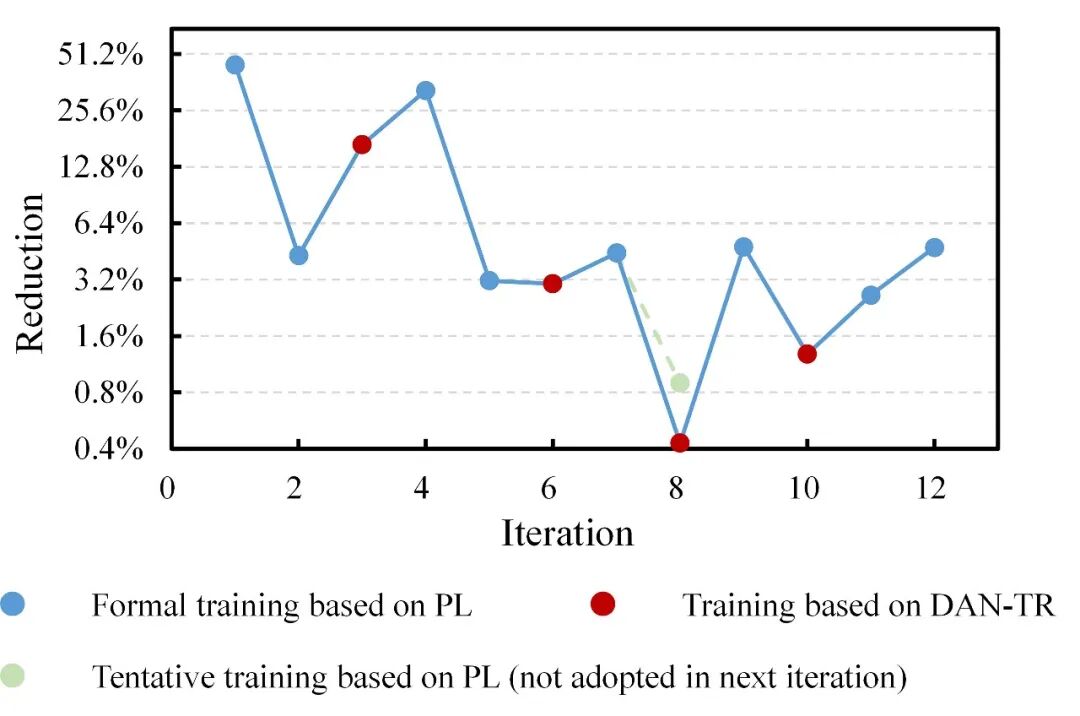
包含5个样本的小规模数据集上验证集Loss降幅
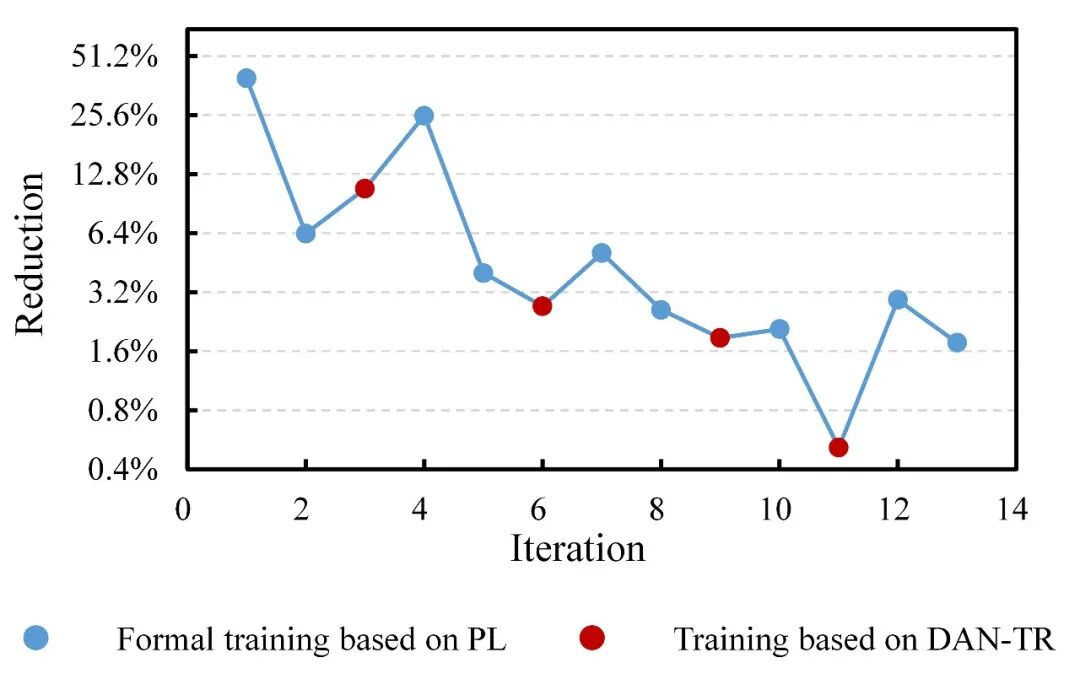
包含20个样本的小规模数据集上验证集Loss降幅
测试集上的测试结果也表明,迭代自迁移方法可以带来显著的性能提升,误差(MSE)下降幅度70%-84%。对典型样本进行可视化后同样可以看出,经过迭代自迁移训练,模型的精度有显著提升。
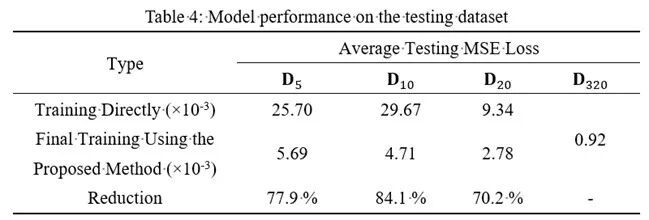
测试集测试结果
(D5、D10、D20、D320分别代表用5个、10个、20个和320个数据训练得到的结果)
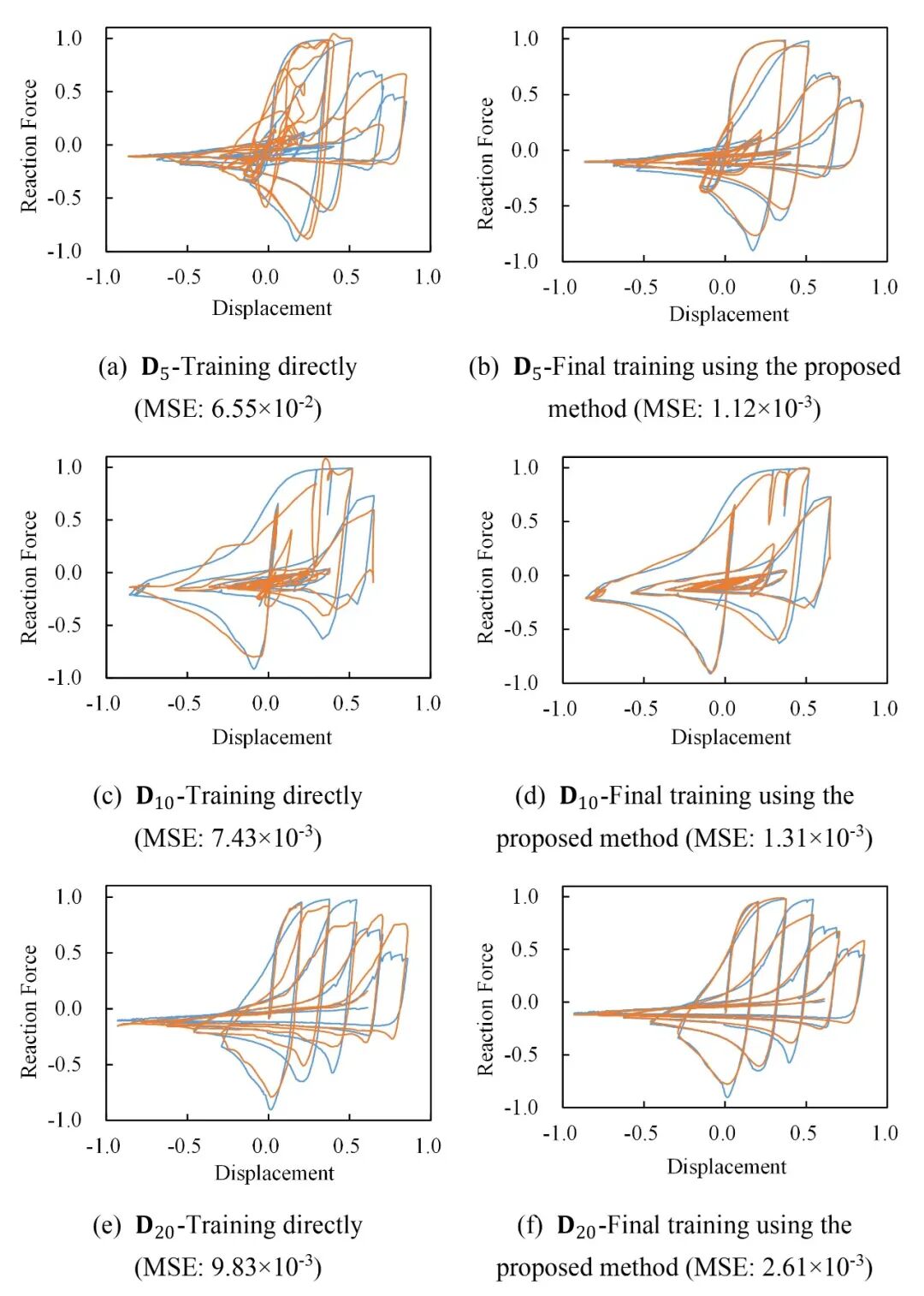
典型样本可视化与对比
(D5、D10、D20、D320分别代表用5个、10个、20个和320个数据训练得到的结果)
4.3 方法对比
本研究开展了迭代自迁移方法和以下典型方法的对比。限于篇幅,对这些既有方法的介绍参见论文正文。对比表明,本研究提出的迭代自迁移方法具有最佳表现。
(1)传统数据增广方法
(2)十字绣网络(多任务学习的典型代表)
(3)带动态掩码的预训练+Finetune策略(在BERT、RoBERTa等网络中广泛采用)
(4)Mean Teacher(基于一致性的半监督学习策略的典型代表),以及Mean Teacher + 伪标签策略
(5)Mixtext(针对文本序列设计的网络架构)
(6)基于BERT模型的直接Finetune
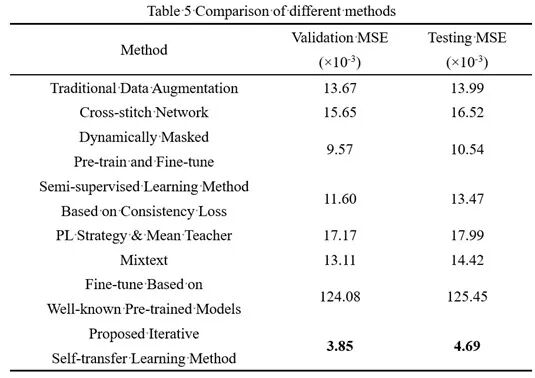
多种典型方法的对比结果
4.4 通用性分析
本研究中,DAN-TR网络的基础架构采用了较为简单、高效的LSTM网络。若研究人员希望采用其他更复杂、拟合能力更强的网络架构,则可以在训练过程的第5步(最终训练)直接基于所得数据集(包含有标签和伪标签样本)开展网络训练,而无需重复第1-4步。这将显著降低网络训练成本。例如,本研究采用清华大学樊健生、王琛等提出的UA-Seq2Seq网络架构,在上述基于LSTM获取的最终数据集上开展网络训练,较直接训练而言依然取得了显著的性能提升。其中,验证集MSE下降37%-61%;测试集MSE下降16%-56%。
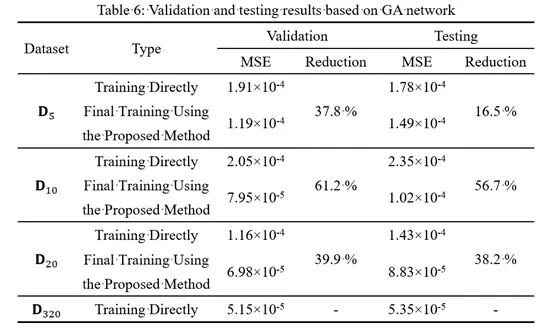
直接基于UA-Seq2Seq网络架构的训练结果
(D5、D10、D20、D320分别代表用5个、10个、20个和320个数据训练得到的结果)
5
结论
本研究提出了适合长序列回归任务的迭代自迁移方法,在仅有小规模数据集的前提下,显著提升深度神经网络的拟合精度。案例分析表明,本文方法可以提升小样本数据集条件下的模型性能近1个数量级,比多种既有方法更优,且具有良好的通用性。
6
联系方式
如您有任何问题/建议/意见,欢迎联系:
徐永嘉博士 [email protected]
---End---
相关研究
特刊征稿
专著
人工智能与机器学习
---结构智能设计
---其他土木工程领域人工智能研究
城市灾害模拟与韧性城市
高性能结构与防倒塌
新论文:抗震&防连续倒塌:一种新型构造措施
长按识别二维码,关注我们的科研动态
